There’s a well-described concept in clinical medicine known as alert fatigue. It’s a real neurologic process where the brain starts to tune out alerts and alarms in an environment with a lot of alerts and alarms. Think about the ICU, where ventilators are constantly beeping about excessive PEEP or something, an intravenous pole is beeping because the line is kinked, a telemetry monitor is flashing for rapid atrial fibrillation. When this is the background that you’re dealing with, it’s possible that truly important alerts and alarms get missed.
One of the challenges of integrating AI into medicine is to avoid alerting providers so much that they start ignoring the alerts, even when they’re correct. What that means is that the table stakes for AI systems are not just accuracy. For an AI system to be useful, it has to be accurate but also meaningfully change a provider’s behavior — and for that behavior change to meaningfully improve a patient outcome.
That’s actually a pretty tall order. But when I think about alerts, alarms, prompts, and AI, I do think of the handful of times in my medical career where I’ve been truly grateful for an interruption to my clinical workflow. There have been a few times where something has popped up in the electronic health record and I said, “Holy shit, I almost missed that.” Maybe a critical drug-drug interaction, maybe an allergy finding, maybe an alert about a particularly abnormal lab value. Those moments in medical care, which in my own brain I call “oh shit” moments, have the nicer name of missed opportunities for diagnosis. They are a place where AI might be not only be useful but embraced. And a new study has just been published that tries to evaluate how well AI can capture those “oh shit” moments.
I want to tell you about this study, which appears in JAMA Network Open. It evaluates the ability of several large language models (LLMs) to correctly identify patient situations where there was a missed opportunity for diagnosis. That should lead immediately to the question: How do you determine which patient had a missed opportunity for diagnosis? The authors are fairly clever here.
They identified two cohorts of patients who were seen in the emergency department (ED). One was a group that was seen and discharged from the ED but presented again within the next 72 hours. One group comprised patients who were seen and evaluated in the ED and admitted to the floor but required transfer to the ICU within the next 24 hours.

In both cases, you might imagine that something was there initially that a provider could have missed. If it’s possible for an AI to not miss in that situation, it might be a circumstance where a gentle reminder to the provider to think about diagnosis X or treatment Y would result in them being grateful as opposed to indignant.
Now I know what you’re thinking. Not everyone who shows up in the ED and is discharged and comes back within the next 72 hours had some sort of missed diagnosis. So the first step in this study was for providers to manually adjudicate each of these cases and try to determine if there was something at the time of initial presentation that, if caught, would have led to a different outcome.
For example, in one case, a patient was admitted to the floor but transferred to the ICU within 24 hours. At the time of presentation to the ED, the patient had a large anion gap, an elevated glucose level, and acidosis. However, diabetic ketoacidosis was not diagnosed in the ED. Catching that in real time could have meaningfully changed the clinical course. In contrast, one patient presented with low back pain but no other concerning symptoms and was discharged from the ED. This patient presented within the next couple of days with findings concerning for an epidural abscess. Although that’s obviously a bad outcome, there was nothing present in the initial ED visit to suspect that diagnosis or indicate a more advanced workup. No fever, no elevation in white count, no localizing neurologic symptoms. So this would not be classified as a true missed diagnosis.

Overall, across 288 cases, the authors identified 39 (about 13.5%) situations where there was a meaningful opportunity for diagnosis that could have changed the clinical outcome. We take this as the ground truth.
This is where it gets interesting, because we can present all of this data — including the notes from the ED visit — to various LLMs, and ask them quite simply: Is something being missed here? Yes or no? We can also ask them: How likely is it that something is being missed here? Place that on a spectrum, a percentage chance. And because they’re LLMs, we can also ask them what is being missed here?
That’s just what the researchers did. They presented this data to multiple models, including Claude Sonnet 4, Claude Sonnet 4.6, Claude Opus 4.6, Gemini 3 Pro, GPT-5, and GPT-5 mini.
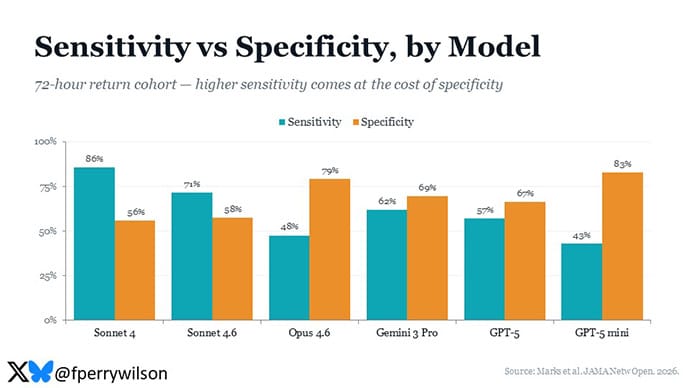
There are a number of interesting analyses we can look at with the output. First, we can say: Of that minority of patients who truly had a missed opportunity for diagnosis, how often did the LLM pick up on something? This is the sensitivity of the LLM to misdiagnosis. You can see the range of performances here, with Claude Sonnet 4 performing best and GPT-5 mini performing worst.
But sensitivity is a double-edged sword. In general, when it comes to diagnostic testing, a test that is more sensitive — while it will be better at capturing the cases of interest — will also tend to drag in a bunch of unrelated cases. In other words, highly sensitive models tend to have a high false positive rate — or, put another way, a low specificity. This is the classic sensitivity-specificity trade-off, and interestingly we see something like this across all the models. The most sensitive model, Claude Sonnet 4, is one of the least specific, and vice versa.
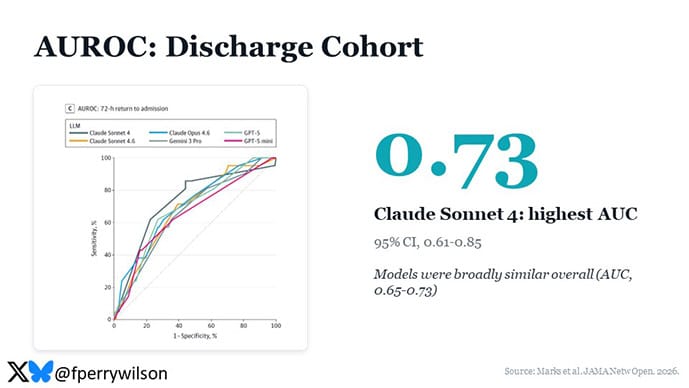
You can combine sensitivity and specificity into an aggregate metric using the area under the receiver operator characteristic curve, which gives sort of an omnibus view into how good a diagnostic test this thing is, and you can see the results here, with Claude Sonnet 4 coming out on top in the discharge cohort.
So out of the gate here, we have at least some evidence that these models, when presented with the same data that ED physicians are presented with, can potentially flag patients for a second look. You can imagine implementing this clinically: When the doctor is attempting to discharge a patient from the ED and the LLM pops up and says, “Hey Doc, are you sure? Have you thought about diabetic ketoacidosis with this patient?”
Of course, this is where the rubber really meets the road, because when that pops up and it’s correct and you haven’t thought about diabetic ketoacidosis, you’re incredibly thankful. But if it pops up all the time, and particularly if it pops up and tells you that there is a problem that the patient doesn’t actually have, the natural human response is to start dismissing that pop-up as soon as it happens. False positives tend to destroy trust in medical AI systems. There’s a sort of dark truism here, which is that false positives are so bad for medical trust in AI that it is better to miss positive cases than to flag false positives. When AI jumps in to tap you on the shoulder, it better be correct.
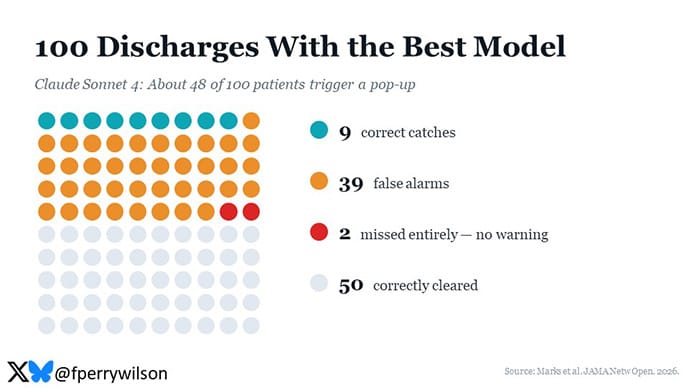
So I think the best way to examine systems like this is to imagine how they would work across a few ED shifts. Let’s say you’re an ED provider and you’re going to discharge 100 patients. To anchor this example, I’ll use the best performing model in terms of area under the curve which was Claude Sonnet 4. Using this best model, out of those 100 patients, about 48 will pop up as you enter that discharge order and say, “Hey Doc, did you think about X?” Of those, about nine will be correct. You’ll slap your head and say, “Oh no, I didn’t think about X, you’re right, this patient needs to be admitted.” And the rest (about 39) will be false positives. You’ll laugh at the silly AI and say, “No, no, they’re fine, I’m going to discharge them anyway.” A few days will pass, and about two patients will come back to the ED who even the LLM didn’t warn you about.
Would a system like this be embraced in clinical practice? My gut feeling is no, not with numbers like this. But it’s another AI truism that if you don’t like the performance of a model, wait a couple of weeks and come back. Because of the timeline of publications of this kind of literature, these modelsmaxed out at the frontier systems of early 2026 —GPT-5, Gemini 3 Pro, and Claude Opus 4.6 — were all last used in March 2026. We now have several successor models to these that may well perform better.
I do have some meta-concerns about using LLMs in this fashion. LLMs make me nervous because they are dependent on their prompt, and the authors went to great lengths to refine their prompts to get the exact output they wanted.
But sensitivity to initial conditions like that can be trouble. We learned this from Jurassic Park, after all. LLMs are also stochastic in their outputs, which is to say, given the same input, they will not always generate the same output. And when it comes to medical care, that type of variability feels problematic, even if I can’t put my finger on exactly why it should be. It’s clear, though, that the authors were worried about this as well, as in the supplement they note that they set the temperature of the models they were using to zero. This essentially minimizes the randomness in model output, but that comes at a cost: With the dial turned all the way down, the model just hands back its single most-likely answer every time, so you lose any sense of the range of possibilities it was weighing. And if that one answer happens to be wrong, it will be wrong confidently and consistently, with no variation to tip you off that it might be worth a second look. In fact, other studies of LLM usage in medicine have found that turning the temperature down increases reproducibility but decreases accuracy.
Are these models ready to be integrated into the electronic health record to reduce or eliminate the “oh shit” moments in medicine? We’re probably not there yet, but I’m extremely confident we will get there. At the rate these models are improving, I would expect that AI overview of clinical care will become commonplace. In fact, there is a future out there where the failure to provide AI overview of clinical care may even be considered malpractice.
I’m reminded of that old curse: May you live in interesting times.
F. Perry Wilson, MD, MSCE, is an associate professor of medicine and public health and director of Yale’s Clinical and Translational Research Accelerator.
https://www.medscape.com/viewarticle/can-ai-save-doctors-missed-diagnoses-2026a1000lvl